Profiluri abstracte de la punctul de stabilitate structurală la tendințele universale, Familie factori specifici, precum și conexiuni între limbile antice (traducere automată)
- Pentru a adăuga o notă , evidențiați un text. Ascunde notele
- Asigurați-un comentariu general
1 Limbă și Genetică, Institutul Max Planck pentru psiholingvistică, Nijmegen, Olanda,2 Limba și Cogniție, Institutul Max Planck pentru psiholingvistică, Nijmegen, Olanda,3 Donders Institutul pentru Brain, Cognition și comportamentul, Radboud University Nijmegen, Nijmegen, Olanda,4 Radboud University Nijmegen, Nijmegen, Olanda
Rezumat Sus
Limba este cel mai bun exemplu al unui sistem evolutiv culturală, în măsură să mențină un semnal filogenetice peste multe mii de ani. Stabilitatea temporală (conservatorismul) din vocabularul de bază este relativ bine înțeles, dar stabilitatea a proprietăților structurale ale limbajului (fonologie, morfologie, sintaxa) este încă neclar. Aici am raportat o vastă anchetă filogenetic Bayesiană a stabilității structurale a numeroase caracteristici EUROPAGES in mai multe familii de limbi și vom introduce o nouă metodă de analiză a relațiilor dintre profilurile "stabilitate" a familiilor de limbi. Am constatat că există o puternică componentă universală în întreaga familii de limbi, sugerând existența unor lingvistice universale, constrângerile cognitive și genetice. În acest context, cu toate acestea, fiecare familie are o limbă distinctă profilul de stabilitate, iar aceste profiluri grupează pe zone geografice, precum și posibilele relații profunde genealogice. Aceste profiluri de stabilitate par a arăta, de exemplu, relațiile istorice dintre vechi siberiana si familiile americane lingvistice, presupuse a fi separate de cel puțin 12000 ani, și eventualele legături între familii eurasiatice. Am găsit, de asemenea, sprijin preliminar pentru evolutia punctual de caracteristicile structurale ale limbajului din familii, tipuri de caracteristici și zone geografice. Astfel, aceste proprietăți de nivel superior de limba văzută ca un sistem evolutiv ar putea permite investigarea conexiunilor între limbi antice și vărsat lumină asupra popularea lumii.
Referirea: D Dediu, Levinson SC (2012) Profile Rezumat de la punctul de stabilitate structurală la tendințele universale, de o familie de factori specifici, precum și conexiuni între limbi antice. PLoS ONE 7 (9): e45198. doi: 10.1371/journal.pone.0045198
Editor: Alex Mesoudi, Universitatea Durham, Marea Britanie
Primite: 31 octombrie 2011; acceptate: 17 august 2012; Publicat în: 20 septembrie 2012
Drepturi de autor: © 2012 Dediu, Levinson. Acesta este un articol cu acces liber distribuit sub termenii Licenței Creative Commons Attribution, care permite utilizarea nerestricționată, de distribuție, precum și reproducerea în orice mediu, cu condiția autorului original si sursa sunt creditate.
Finanțare: Aceasta lucrare a fost sustinuta de Institutul Max Planck ( http://www.mpg.de ).Finanțatorii nu a avut nici un rol in proiectarea de studiu, colectarea și analiza datelor, decizia de a publica, sau de pregatire a manuscrisului.
Interese concurente: Autorii au declarat că nu există interese concurente.
Introducere Sus
1 istorice lingvistica [1] investighează relațiile genealogice dintre limbi folosind o metodologie de timp onorat și complex [2] . Recent, paralele izbitoare între limbă și alte sisteme evolutive - biologice și culturale - au fost identificate [3] , [4] a determinat o utilizare din ce în ce succes a metodelor moderne de filogenetice inspirate din biologie evolutionista [5] - [9] . Un domeniu important de interes actual se referă la stabilitatea în timp a diferitelor componente ale limbajului și ceea ce pot dezvălui despre istoria umană și constrângerile universale cu origini în cunoașterea umană și învățarea [6] , [7] , [10] . Ratele de înlocuire în vocabularul de bază (sau Swadesh lista [11] ) - 200 de wordforms impare care exprimă sensuri cele mai stabile din limba - sunt relativ bine înțelese [12] , cu frecvența de utilizare a fi sugerat ca un factor explicativ important în lucrările recente de Pagel si colegii [4] , [5] .Aceste rate par să fie corelate între familii de limbi, astfel încât sensurile lexicale stabile, de exemplu, limbi indo-europene, de asemenea, tendința de a fi stabile în limbile Bantu sau austroneziană [5] , [8] , [13] , precum și între regiuni extrem de largi geografice [14] .Timedepth maximă de reconstrucție istorică folosind metode de vocabular este, în general, recunoscut să mintă, la aproximativ 10.000 de ani înainte de a prezenta [15], lăsând speranța insuficient de conectare a 250 de familii lingvistice + ale lumii [16]sau de a descoperi relații care se întind înapoi în Pleistocen . Cu toate acestea, este posibil ca caracteristici structurale (cum ar fi aspecte ale inventarelor fonem, morfologie și sintaxă) ar putea fi de bine în măsură să păstreze informații despre relații mai vechi. Unul a adăugat nivelul de complexitate în studierea astfel de caracteristici structurale este că ele reprezintă abstracțiuni peste modele din multe limbi și că valorile lor includ în mod necesar un anumit grad de subiectivitate. De exemplu, chiar concepte aparent simple și necontroversate, cum ar fi "f" și "verbul" prezintă dificultăți atunci când au văzut mai multe limbi foarte diferite [17] face eco-lingvistice comparații extrem de dificil [18] . În acest context, întrebările sunt apoi (I.), dacă este posibil pentru a izola cele mai stabile structurale, asemanatoare cu vocabularul de bază, conservatoare, și (II.) ce ar putea să dezvăluie despre evolutia diversității lingvistice curente.
Din păcate, stabilitatea caracteristicilor structurale ale limbajului este în prezent mai puțin înțelese și sa dovedit a fi mai controversată din cauza constatărilor empirice și pozițiile divergente teoretice. Există mai multe abordări posibile la definirea și cuantificarea stabilitatea caracteristicilor structurale (a se vedea, pentru unele exemple recente [19] - [22] ), variind în accentul pus pe verticale (genealogice) și pe orizontală (de contact) procese în limba. Momentan nu sunt traduceri, cum ar fi "Nichols, [16] lucru în tipologia lingvistică și abordările mai recente filogenetice de Dunn și colegii [6] , [10] , că trăsăturile structurale sunt suficient de stabile pentru a menține semnale filogenetice ale relațiilor dintre limbile de peste mult mai profunde adâncimi de timp decât de vocabular cele mai conservate, precum și că acestea ar putea fi chiar mai bine decât markeri genetici la conservarea unui semnal istorică verticală împotriva amestecului populației [10] . Pe de altă parte, o comparație recent realizat de Greenhill si colegii [8] de caracteristici structurale și de vocabular de bază sugerează că structura și de vocabular au stabilități similare (o constatare, de asemenea, susținută de o abordare diferită [22] ), dar caracteristicile structurale ar putea fi mai predispuse la împrumuturi, ceea ce le face mai putin surse de informații de încredere cu privire la relațiile dintre genealogice limbi (a se vedea, de asemenea,[23] pentru o sugestie similară). Studiul sugerează că în special stabilitatea caracteristicilor structurale variază în funcție de familii de limbi [8] , ceea ce duce autorii de a pretinde ca rezultatele lor "nu susțin existența unui set de caracteristici tipologice universal stabile" (p.6). Această concluzie pesimistă cu privire la perspectivele de utilizare a caracteristicilor structurale în scopuri istorice pot par a fi susținută de concluziile recente ale Dunn si colegii [7] că modelele de evoluție corelată între tipurile de ordinea cuvintelor sunt diferite între patru familii de limbi majore.Acest lucru este în contrast evident, cu toate acestea, cu raportul de Dediu [9] că există un acord cu privire la stabilitatea de caracteristici structurale EUROPAGES un esantion mare de familii de limbi, ceea ce sugerează că stabilitatea o caracteristică structurală special, tinde să fie independentă de limbă familie în cauză.
Cum suntem noi să împace aceste constatari divergente? Sunt caracteristici structurale mai stabile sau mai puțin stabil decât vocabularul de bază? Sunt unele caracteristici structurale în mod inerent mai stabile decât altele (într-un mod similar cu vocabularul de bază) sau este stabilitatea lor pe deplin determinată de proprietățile idiosincrazice și contingențe istorice specifice fiecărei familii de limbi? Și putem folosi caracteristicile structurale to-peer în trecut profundă, dincolo de orizontul 10.000 de ani de metoda comparativă clasică în domeniul lingvisticii?
Acesta va lua un efort mult mai susținut pentru a beneficia de reconstrucția istorică structurale în fața vom avea răspunsuri definitive la aceste întrebări. Dar între timp noi credem că, prin adoptarea unei abordări mai abstract am putea fi în măsură să ofere o reconciliere a acestor opinii divergente, oferind în același timp bazele importante pentru progresele viitoare în acest domeniu. Ne arată aici că evoluția culturală a caracteristicilor structurale este simultan modelată de tendințele universale , familie, factorii specifici de limbă și procesele profunde genealogice și suprafață care acționează în întreaga familii de limbi. Astfel, dihotomia dintre tendințele universale și a limbajului de familie specificitate în ceea ce privește stabilitatea structurală este unfals una, dat fiind faptul că toate cele trei niveluri sunt prezente în același timp.Această partiționare cu trei căi de stabilitate structurală între familii de limbi este metaforic similar cu structura speciei noastre: suntem, în același timp, în mod fundamental aceeași ca și celălalt fiind în același timp indivizi unici, care sunt mai asemănătoare în cadrul grupurilor de rudenie decât peste ei. Sau, așa cum Murray și Kluckhohn [24] a pus-o "Fiecare om este în anumite privințe (a) la fel ca toți ceilalți oameni, (b) ca niște alți oameni, (c) ca nici un alt om" (pag. 53). Componenta universal - Murray și a lui Kluckhohn (a) -, prin care anumite aspecte ale limbajului tind să fie mai stabile în toate familiile, ar putea indica deviațiilor biologice și cognitive care afectează achiziție limbă, de utilizare și de prelucrare [25] , [26] . Cele lingvistice de familie factori specifici - Murray și a lui Kluckhohn (c) - includ affordances idiosincrazice pentru schimbarea limbii [7] și accidente istorice. În cele din urmă, diferențele dintre familiile nu sunt în totalitate neconstrâns - Murray și a lui Kluckhohn (b) - și ne arată aici că acestea ar putea fi modelat de relațiile istorice adânci între limbi.
Mai degrabă decât direct, folosind modelele de valori ale caracteristicilor structurale pentru a deduce relațiile istorice dintre limbile, ne propunem aici, investigarea modelele de stabilitate a acestor caracteristici în întreaga familii de limbi. În acest mod, vom folosi familii de limbi construite independent și înainte de aplicarea metodei noastre (și utilizând în mod ideal, metoda istorică lingvistice comparative) pentru a deduce stabilitatea de caracteristici structurale în aceste familii - ceea ce noi numim aici, familia limbii profilul de stabilitate . În esență, profilul de stabilitate al unei familii de limbi reprezintă stabilități relative (de la cea mai stabilă pentru cea mai instabilă), de un set de caracteristici structurale din această familie. Profilul de stabilitate al unei familii este un concept abstract, matematic, care este, în sine, complet agnostic cu privire la existența sau nu a tendințelor universale, procesele lingvistice specifice familiei și intra-familiale. Doar seturi de profile de stabilitate calculate pentru mai multe familii se poate pune în lumină astfel de chestiuni, prin relațiile lor reciproce.
Noi folosim aceste profiluri de stabilitate estimate pentru mai multe familii de limbi pentru a deduce relații mai profunde dintre aceste familii, pe ipoteza că, în timpindividuale caracteristici structurale ar putea fi relativ ușor transferate în întreaga limbă (și chiar familii de limbi) Frontierele sau schimbari intr-un timp scurt, profilurile de stabilitate ar putea fi mai rezistente la astfel de procese. Acest lucru se datorează faptului că un profil de stabilitate rezumă schimbările istorice ale întregului set de caracteristici structurale dintr-o serie întreagă de limbi înrudite în timpul intreaga istorie a familiei . Îndatorării una sau mai multe caracteristici nu s-ar schimba în mod dramatic profilul de stabilitate al familiei limba sau familiile implicate, care necesită modificări la sistemele coerente de mai multe inter-legate de caracteristicile în cazul în care componentele care nu sunt liberi să schimbe la voință (ca Meillet pus-o "... Que chaque langue Forme ne Système ou tout tient sine ... ", în traducerea noastră din limba franceză:" ... ca fiecare limba este un sistem în care toate părțile interacționează ... ") [27] ). Desigur, există cazuri de restructurare importantă în cazul în care mai multe caracteristici schimba împreună, și în situații de contact intense această restructurare poate fi masiv, dar probabil foarte rar afectează membrii suficiente ale unei familii de limbi într-o asemenea manieră coerentă, care se va modifica profilul familiei stabilitatea. Noi sugerăm ca, la fel ca în genetica [28] , unele caracteristici ar putea fi hub-uri în rețeaua structurală a sistemului limbii în timp ce altele sunt mai periferice, cu primul tip mai rezistente la schimbare și de împrumut și două mai predispuse la aceasta, așa cum a propus de ipoteza (extinsă) complexitatea în biologia evoluționistă [29] , [30] . Un astfel de cont poate să fie în concordanță cu explicația frecvența dovedit a juca un rol în vocabular [4] , în sensul că structurile de noduri pot fi mai frecvent utilizate în schimburile lingvistice și, astfel, rezistente la schimbare.
Pentru a urmări aceste chestiuni, am examinat stabilitatea unui set larg de caracteristici tipologice EUROPAGES in mai multe familii de limbi, sub o serie de ipoteze diferite pentru a testa robustețea concluziilor. Aici, am înțeles de stabilitateîntr-un genealogic (pe verticală), context ca tendința de o caracteristică structurală a păstra valoarea sa ancestrala a lungul limba ulterior desparte. Astfel, o caracteristică stabilă va tind să aibă aceeași valoare în toate limbile coborât din aceeași proto-limba.Acest lucru este posibil, dar unul sensul de stabilitate, care se aplică la tipologia lingvistică, dar este de tip prezent cel mai bine cuantificate și înțelese de stabilitate, datorită paralele în biologia evoluționistă (a se vedea secțiunea "Comparând stabilitate structurală în întreaga metode"). Pentru o familie anumită limbă, am estimat stabilitate a unui set de caracteristici utilizând o abordare filogenetică Bayesian, care ia dat ca un arbore genealogic limba și valorile observate de caracteristici în limbile familiei. O relevanță aici este faptul că software-ul Bayesian filogenetic produce distribuții posterioare ale estimări ale statelor ancestrale (valori care caracteristicile de care aveau la nodurile arborelui-interne) și ratele la care valorile artistice s-au schimbat peste copac.
În scopul de a controla pentru diverse surse de posibile erori, am folosit diferite filogenetice pachete software bayesiene, cuantificari diferite de stabilitate, opțiuni diferite outgroup, clasificările lingvistice și codificările de date [9] , rezultând în 12 seturi de date distincte. Datorită ipoteze distincte și codificările, seturile de date au grade diferite de rezoluție, dar rezultatele se coreleaza la un nivel foarte ridicat, în consecință, dar numai pentru scopuri de prezentare, vom ilustra aici cu un set de date singur reprezentant (a se vedea Materiale și metode ). Vom compara estimările care rezultă stabilității în familii de limbi și arată că, în plus față de un acord de fundal în funcție de stabilitate, variatia de stabilitate între familii de limbi este punct de vedere geografic și istoric model.
Această abordare, folosind mai mare nivel proprietati ale limbii au văzut ca un sistem evoluează în timp, promite să deschidă o fereastră asupra proceselor care au modelat preistorie umană pe o scară de timp adâncă situată dincolo de metodele disponibile în prezent.
Rezultate de top
Bazându-se pe Atlasul Mondial al structurilor de limbă [31] , [32] , am estimat stabilitate a unui set larg de caracteristici structurale (cum ar fi stocurile fonem, ordinea cuvintelor sau tipuri de negare, a se vedea Materiale S1 pentru lista completă) peste mai mult mult de 50 de familii de limbi în total de folosind o abordare filogenetică Bayesian. Mai precis, pentru a evalua soliditatea rezultatelor, am utilizat două pachete diferite bayesiene filogenetice software (MrBayes 3 [33] și BayesLang[9] ), mai multe alegeri outgroup, trei clasificări diferite limbi (WALS [31] , Ethnologue[34 ] și o colecție de mai multe ortodoxe clasificărilor lingvistice istorice [35] ) și două tipuri de codificările de date (binare și polimorfă), rezultând în 12 seturi de date distincte ( Materiale și metode , secțiunea de date primare și estimarea stabilității ). Această procedură ne-a permis pentru a controla influența diferitelor surse de posibile erori, inclusiv metoda specifică pentru estimarea ratelor de schimbare pe filogeniile, codificare deviatiilor în date, precum și efectul de clasificările de limbi în unități genealogice și a gradului de Rezoluția din aceste clasificări. Deoarece cele două rezultatul codificările în diferite numere de polimorfa (Raport binar) caracteristici, precum și două pachete software utilizate au diferite ipoteze și cerințe minime, componența celor 12 seturi de date rezultate diferă în detaliu (a se vedeaMateriale S1 ), dar rezultatele raportate de mai jos sunt similare.Caracteristici structurale ale Limba evolueze în Exploziile Punctuational
Atkinson si colegii [36] au aratat recent ca vocabularul de bază nu evoluează treptat, dar prezinta exploziile de limba rapidă ca urmare a schimbării desparte. În esență, cantitatea de evoluția pe calea care duce de la rădăcina arborelui într-o limbă este pozitiv corelată cu numărul de noduri (împarte) pe calea. Folosind o metodologie complexă care controlează pentru înrudirea filogenetică și așa-numitul "nod-densitate" artefact [37] , în familii de limbi trei (indo-europeană, bantu și austroneziană), ei află că între 9,5% și 33% din schimbările de vocabular se datorează exploziile punctuational în jurul valorii de evenimente de despicare [36] . Aici vom folosi o metodă mult mai simplă de a explora posibilitatea ca schimbările structurale ar putea să urmeze, de asemenea, un model de punctuational prin calcularea corelației dintre lungimea și calea de numărul de noduri ( Metode Secțiunea: evolutia punctat ).Am constatat că în toate familiile lingvistice și seturi de date, corelația dintre lungimea calea și numărul de noduri este foarte mare (în intervalul 0.65-0.80, medie = 0,75, SD = 0,046), ceea ce sugerează că exploziile punctuational ar putea explica aproximativ 50% din schimbările structurale. Există diferențe mari între familii de limbi și seturi de date ( Materiale S1 ) cu cele mai multe familii care arată o corelație pozitivă (interval -0.66-0.87, medie = 0.37, SD = 0,32; un eșantion test t față de 0:
Relațiile între profilurile de stabilitate Sugestie Tendinte universale în programele de stabilitate structurală
După cum se explică în detaliu în Materiale și Metode , profilul de stabilitate al unei familii de limbi surprinde stabilități de un set de caracteristici structurale în evoluția acelei familii. Acest profil de stabilitate pot fi vizualizate ca un punct într-un multi-dimensională stabilitate hiper-cub (a se vedea figura 1 și Metode Secțiunea: profilul de stabilitate al unei familii de limbi ), determinate de caracteristicile luate în considerare. În orice set de date dat, există mai multe familii lingvistice, precum și pentru fiecare familie am calculat profilul său de stabilitate, care reprezintă toate caracteristicile "stabilități în această familie. Un astfel de profil poate fi vizualizat ca un punct în stabilitatea multi-dimensional hiper-cub determinat de caracteristicile structurale avute în vedere în setul de date, precum și profile de toate familiile din setul de date sub forma unui nor de astfel de puncte.
Figura 1. Stabilitatea hiper-cub pentru două caracteristici  și
și  , în profilurile de stabilitate de trei familii de limbi
, în profilurile de stabilitate de trei familii de limbi  ,
,  și
și  iar distantele de stabilitate între familii de limbi (indicat pentru
iar distantele de stabilitate între familii de limbi (indicat pentru 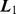 și
și  ).
).
Vă rugăm să rețineți faptul că 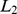 și
și 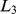 sunt foarte aproape de în acest spațiu.
sunt foarte aproape de în acest spațiu.
doi: 10.1371/journal.pone.0045198.g001În primul rând, am comparat forma relațiilor dintre profilurile de stabilitate ale familiilor lingvistice cu cele așteptate de la o distribuție aleatorie, și a constatat că profilurile de stabilitate din familii de limbi sunt mult mai asemanatoare (mai mult grupate în stabilitatea hiper-cub) decât era de așteptat Șanse de (
Această constatare susține și completează rezultatele noastre anterioare [9] , a obținut folosind o metodologie diferită pentru compararea stabilității caracteristici structurale din familii de limbi. Clasament consens între cele 12 seturi de date de aceste caracteristici, de la cea mai stabilă pentru cea mai instabilă, este dat în S1 materiale (a se vedea, de asemenea, [9] ), precum și sus și de jos 15 sunt prezentate în tabelul 1 . Lucrări în curs care implică primul autor (Dediu, D. & Cysouw, M. în curs de pregătire , unele aspecte structurale ale limbii sunt mai stabile decât altele: O comparare a șapte metode), comparând șapte metode diferite de conceptualizare și estimarea stabilității structurale caracteristici din literatura de specialitate tipologică lingvistică (inclusiv [9] ), concluzionează că toate acestea sunt de acord în a constatat că unele caracteristici tind să fie mai stabile decât altele (a se vedea secțiunea Comparând stabilitate structurală în întreaga metode ).
Profiluri de stabilitate, de asemenea, arata Modele de similitudine între familii de limbi
Stabilitatea hiper-cub este un spațiu mare-dimensional (având între 68 și 86 de dimensiuni în funcție de numărul de caracteristici considerate) și, în scopul de a vizualiza pe suport de hârtie relațiile dintre profilurile de stabilitate ale familiilor lingvistice în aceste spații, am folosit mai multe -dimensional scalare (MDS; [40] , o tehnica pentru proiectarea matrici la distanță pe un spațiu cu dimensiuni mai mici, cu distorsiuni minime) și rețele (folosind vecina-Net [41] cum a fost transpusă în SplitsTree4 [42] , o metodă de a reprezenta o Spațiu de arbori probabile, dar parțial contradictorii). Am subliniază că atât parcelele MDS și rețelele sunt folosite aici doar ca reprezentări vizuale ale relațiilor multi-dimensionale între profilurile de stabilitate, și ne avertizează cu privire la interpretarea cu tărie în mod automat aceste rețele într-un mod filogenetic. Similare (vecina) profilurile de stabilitate ar putea fi un rezultat al mai multor factori, inclusiv coborârea dintr-un strămoș comun, de contact și de împrumut, șansă, sau a diferitelor tipuri de constrângeri asupra schimbării limbii.Ambele metode relevă existența unor modele izbitoare de variație din familii de limbi, care arată a priori neașteptate clustere geografice (a se vedea figurile 2 și 3 ilustrează același set de date, și Materiale S1 pentru toate cele 12 de seturi de date): familiile americane lingvistice tind să se grupeze de-a lungul geografică (linii de Sud, Centrală și de grupuri de Nord) și Eurasia de Nord-Est (siberiana) familii de limbi sunt atrași de grup american ( Figurile 2 și 3 , negru săgeată). Tendințele mai slabe la gruparea sunt, de asemenea, prezentate de către Eurasia (cu excepția regiunii Nord-Est), și Africa (cu excepția Khoisan ) familii de limbi. Interesant, limbile australieni și papuas sunt foarte îndepărtat unul de altul. Khoisan familii și Australia sunt valori aberante, departe de toate celelalte familii.
Figura 2. multidimensională scalare (MDS) Terenul a relațiilor dintre profilurile de stabilitate ale familiilor lingvistice pentru setul de date EBP.
Indicat sunt primele (orizontal) și al doilea (pe verticală) dimensiuni. Am distins zece regiuni geografice reprezentate de o culoare distinctă și o singură cifră, după cum urmează: America de Sud ( 0 , albastru închis), America Centrală ( 1 , albastru), America de Sud ( 2 , albastru deschis), Africa de Sud ( 3 , negru) ,Africa de Nord ( 4 , roșu), Eurasia ( 5 , roz), Asia de Sud ( 6 , portocaliu), Oceania ( 7 , verde), Papua-Noua Guinee ( 8 , verde închis) și Australia ( 9 , cyan). Familiile lingvistice sunt reprezentate prin litere mici alocate singur caz, în ordine alfabetică, pe regiuni geografice, astfel cum și australian ( 9a ). Se poate observa că cele mai multe dintre familii de limbi americane se deosebesc de celelalte prin prima dimensiune (partea stângă), cu respectarea nord (partea de jos) -. Sud (partea de sus), direcția geografică, precum și (a doua dimensiune) Eurasia ocupă partea de jos-dreapta cadran în timp ce Asia de Sud șiOceania , precum și de grup împreună. Interesant, Chukotko-Kamchatkan ( 5b ; marcat cu o săgeată neagră) clustere cu familiile (Europa Centrală și de Nord), limba americană. A se vedea figurile suplimentare în S1 materiale pentru toate cele 12 seturi de date.
doi: 10.1371/journal.pone.0045198.g002
Figura 3. Reprezentarea Rețeaua a relațiilor dintre profilurile de stabilitate aceleași ca în Figura 2 (aceleași convenții se aplică).
Clustere aceeași ca în figura 2 se poate observa, dar atașarea de Chukotko-Kamchatkan ( 5b ; marcat cu o săgeată neagră) este acum mai clară cu America de Nord familii algic ( 2a ), Penutian ( 2d), Wakashan ( 2f ), precum și America Centrală Uto-Aztecan ( 1d ), a cărui gamă geografică, de fapt, se extinde și în America de Nord. A se vedea figurile suplimentare în S1 materiale pentru toate cele 12 seturi de date.
doi: 10.1371/journal.pone.0045198.g003Aceste modele par a avea o componenta geografica
La nivel global, există corelații slabe pentru a Mantel moderate, dar semnificativ [43]între similitudinea profilurilor de stabilitate de familii de limbi și apropierea lor geografică ( Modalitati de secțiune: distantele geografice între familii de limbi ):O modalitate de a înțelege această relație pozitivă între profilurile de stabilitate și distanța geografică este de a afla care subseturi de caracteristici structurale, a maximiza. În cazul în care doar caracteristici foarte stabile sunt necesare, atunci relația reflectă probabil evenimente profunde, în timp ce caracteristici foarte instabile ar putea indica fenomene recente. Am folosit un algoritm genetic bazat pe căutare (Modalitati secțiune: Caracteristici maximizarea corelația dintre stabilitatea și distanțe geografice ) și am constatat că, în general, un subset mic de 10 - 18 caracteristici sunt necesare pentru a maximiza această corelație. Aceste caracteristici includ atât cele de foarte stabile și foarte instabile și tind să difere între seturi de date ( Materiale S1 ), sugerând că, probabil, o combinație de fenomene, atât vechi și mai recente joacă un rol.
Rezistența Statistic al Supra-Modele familiale
În cele din urmă, am testat soliditatea statistică a grupări propuse de către parcelele MDS și rețele, pe de o parte, și de către literatura de specialitate existentă privind relațiile profunde dintre familii de limbi stabilite, pe de altă parte, folosind o abordare permutare ( Modalitati secțiune: Testarea robustețea de grupuri de familii de limbi ). Această metodă compară proprietățile profilurile de stabilitate ale unui subgrup observate de familii de limbi de interes (de exemplu, o anumită propunere pentru "Nostratic", un macrofamily a sugerat, inclusiv diferitele familii de limbi eurasiatice, cum ar fi indo-europeană și uralice [44] ), pentru a Proprietăți de 10.000 de subseturi aleatoriu permutată de aceeași dimensiune ales din ansamblu (sau o parte din ansamblu) set de familii. Pentru fiecare subcategorie de interes am efectuat acest test permutare-robusteții în fiecare din cele 12 seturi de date, obținerea de 12 empirice ("permutare") p -valori. Fiecare dintre aceste 12 p -valori indică probabilitatea că proprietățile de profile de stabilitate ale familiilor lingvistice incluse în subsetul de interes sunt "speciale" în raport cu ansambluri aleatorii de familii de limbi din set mai mare. Astfel, p -valori mai mici decât un a priori un acordAstfel, pentru fiecare subset de interes am efectuat același test statistic (permutări nostru pe baza de test de robustețe) 12 de ori pe cele 12 seturi diferite de date. În mod evident, aceste 12 seturile de date nu sunt măsuri independente, astfel încât standard de meta-analitice instrumente statistice pentru combinarea p -valori [45] ,[46] nu poate fi folosit a priori . Cu toate acestea, cele 12 seturi de date nu corelează perfect, fie, care necesită o abordare mai rafinată a combinarea lor p -valori, descrise pe larg în Metode secțiunea: Combinarea p -valori de la care nu-independente experimente . În rezumat, am combinat aceste empirice p -valori din cele 12 de seturi de date folosind cinci metode, luând conservator cea mai mare p -valoare pentru subset de interes pentru a proteja împotriva fals pozitive (a se vedea tabelele 2 și S1 Materiale ). Vom raporta, de asemenea, numărul de metode (din toate 5) pentru combinarea p -valori care duc la un rezultat semnificativ la
Tabelul 2. robustețea statistică a seturilor de familii de limbi.
doi: 10.1371/journal.pone.0045198.t002Unele modele de Sugerează RelaŃionare posibilă antică
Rezultatele sunt interesante si ar putea oferi sprijin pentru unele propuse macro-familii pe o scară largă. Testul permutare a constatat că profilurile de stabilitate ale familiilor lingvistice americane sunt mult mai asemanatoare decat ne asteptam de noroc (Africa prezinta o sugestie de a forma un grup coerent (
Probabil cea mai bună propunere cunoscut de macro-familie este reprezentată de diferitele versiuni ale Nostratic (a se vedea [44] pentru o evaluare critică) care acoperă mai multe Eurasia și Africa de Nord familii de limbi. Am găsit nici o dovadă pentru o versiune de Nostratic cuprinde afro-asiatic , indo-europeană , dravidiene șiuralice ("V2 Nostratic" din tabelul 1 ;
Există un semnal slab care caracterizează un set de așa-numitele "papuas 'familii, în cazul în care" papuas "înseamnă doar non-austroneziană limbi, în zonele mai Noua Guinee (
În cele din urmă, Reid a lui [47] propunere controversată sugerează că Tai-Kadai șiaustroneziană familii de limbi sunt legate de formarea Austro-Tai grup, am găsit o sugestie slab pentru aceasta ipoteza (
Discutii Sus
Constatarile prezentate aici susțin cu tărie existența unei tendințe universale în întreaga familii de limbi pentru anumite caracteristici structurale specifice să fie intrinsec stabil între familii de limbi și regiuni geografice, astfel cum raportate anterior de către primul autor [9] . O implicație este că cele mai stabile structurale ale limbilor ar putea fi utilă pentru reconstrucția istorică profundă la fel ca partea cea mai conservatoare din vocabular. Cu toate acestea, o problemă potențială este că trăsăturile structurale au un set mult mai limitat de stări posibile decât de vocabular, ar putea duce la saturație mai rapid (explorarea stări posibile), și pierderea corespunzătoare a semnalului filogenetică. În timp ce acest lucru ar putea părea, într-adevăr pentru a limita teoretic structura pe bază de investigații pentru a timedepths puțin adânci decât cele bazate pe vocabularul, mult depinde de ratele de schimbare a structurii Raport de vocabular. În mod clar, luate ca un întreg, modificări de vocabular, la tarife mult mai repede decât structura (putem recunoaște toate modificările în viețile noastre, a se vedea [48] ). Acesta este motivul pentru metodele de vocabular, de obicei, se limitează la nucleul cel mai conservator al lexiconului, deși există excepții importante [48] , [49] . În schimb, lucrările recente de Dunn și colegii [7] , [50]sugerează că, în medie, un anumit cuvânt-Pentru schimbare, de exemplu, apare doar o singură dată, în zeci de mii de ani de evoluție în cadrul unei familii de limbi. Așa cum am arătat aici, în [9] , caracteristicile structurale, de asemenea, diferă în stabilitatea lor, unele fiind labilă, unele extrem de conservatoare. De asemenea, am arătat că această scară de stabilitate are ambele versiuni universal și mai mult la nivel local limitat, toate din care pot fi exploatate în mod judicios pentru explorarea relațiilor istorice adânci între limbi.O altă problemă care ar putea ciuma reconstrucții filogenetice bazate pe caracteristicile structurale este reprezentat de faptul că acestea pot fi afectate de procese orizontale, cum ar fi de împrumut [8] . Desigur, limba de contact afectează toate componentele de limbă [51] , în special de vocabular, și în timp ce listele de vocabular selectate pentru conservatorism (cum ar fi versiunile lista Swadesh) ar putea fi mai rezistente la ea decât restul de vocabular, acestea sunt cu siguranță Nu imun [48] , [52] . Există neînțelegeri semnificative ale rolului de contact în filogenie lingvistice, astfel cum au subliniat în [50] : modificări, indiferent de sursa acestora, vor fi reflectate în continuare profilurile filogenetice de familii de limbi, astfel încât împrumutul de structura nu ar trebui să submineze fundamental inferență de filogenie.De fapt, studii recente de simulare [53] , [54] susțin ideea că inferențele filogenetice sunt robuste la gradul și tipul de procese orizontale care afectează limba. Atunci când estimarea ratelor de schimbare într-un cadru filogenetic - ca rezolvate aici - oricesursă de schimbare care afectează structurile lingvistice vor conta. Astfel, în cazul în care o caracteristică este ușor de împrumutat, aceste modificări vor fi detectate exact așa cum dacă sunt determinate de alte cauze ale schimbărilor limbii. De asemenea, găsim că stabilități estimat de acord metoda noastră filogenetică foarte bine cu cele estimate prin metode care în mod explicit procesele model din orizontale în limba. Mai fundamental, noi credem că modul în care procesele orizontale în limba sunt tratate reflectă întrebări filozofice profunde în ceea ce privește procesele istorice și natura entităților a căror istorie este reconstruit, într-un mod paralel la controversa actuala din jurul transfer orizontal genetică și starea din Pomul Vieții în biologia evoluționistă[55] - [57] .
Metoda propusă aici încearcă să se ia în considerare aceste aspecte (i) prin luarea în considerare un număr mare de caracteristici structurale care să acopere diverse aspecte ale limbii, (ii) prin utilizarea bayesiene filogenetice metode care pot încorpora parțial incertitudinea generată de procesele orizontale în distribuții posterioare , și (iii) de către concentrându-se pe de ordin superior proprietăți ale dinamicii evolutive ale modelelor de caracteristici structurale.
În timp ce susținerea cazului pentru un set de bază de caracteristici structurale stabile din familii de limbi, abordarea noastră, de asemenea, arată că diferențele reziduale în stabilitatea structurală între familiile pot transporta un semnal istoric, care poate fi folosit pentru a arunca lumină asupra preistoriei umane. Am constatat că profilul de stabilitate al unei familii de limbi poarta un semnal care reflectă atât relațiile sale profunde genealogice și a membrilor săi arealul. Controlul de geografie eliminat aproximativ jumătate din clustere de nivel mai înalt de familii de limbi am gasit, sugerând că această similitudine între profilurile de stabilitate nu este pe deplin explicată prin fenomene de contact, lăsând ca explicație principală persistența unor relații profunde genealogice. Cu toate acestea, factoring din geografia este, de asemenea, probabil ca să țină niște relații autentice genealogice, întrucât într-un model de diversificare limba condus de populație splitări, limbile înrudite (și mai târziu, familii) va rămâne, de asemenea, aproape în spațiu geografic, geografie factorii de confuzie și filogenia de bază. Mai mult decât atât, această apropiere geografică promovează, de asemenea, de împrumut între sub-ramuri, promovează schimburi lingvistice, de standardizare, etc Ca cercetările anterioare privind relațiile profunde dintre limbile istorice a menționat [16] , profile structurale ale limbilor pot reflecta atât filogenie profundă și datele de contact vechi. Sprijinirea această contribuție dublă este constatarea noastră că corelație pozitivă între profilurile de stabilitate și distanțele geografice este maximizat printr-un subset de caracteristici care conțin caracteristici atât de stabile și instabile structurale.
Oricare ar fi contribuția efectivă relativă a proceselor de orizontale și verticale în conturarea structurare a profilurilor de stabilitate lingvistice de familie, se pare că aceste profiluri sunt capabili de a conserva legături între vechi familii de limbi. Deși este bine-cunoscut faptul că valorile de caracteristici structurale arată structurare geografică din cauza proceselor de verticale și orizontale, ne-am arătat aici că, profilurile abstracte de stabilitate sunt, de asemenea, punct de vedere geografic model, păstrând, probabil, un semnal de mult mai în vârstă sau mai mare anvergură astfel de procese. De exemplu, gruparea puternic al Americi și limbile siberiene se potrivește modele generale de migrare deduse din arheologie si genetica [58] .Recenta propunere a afiliere lingvistică a Yenisean limbile din Siberia și Na-Dene limbi din America de Nord [59] ar putea reprezenta un exemplu lingvistic potențial mai recente. În sprijinul metodei noastre este constatarea că în timp ce întreaga America, iar în cadrul acesteia, America de Nord și de Sud formează clustere, America Centrală - o zonă bine-cunoscut lingvistice [60] - nu, sugerând faptul că metoda nu este deschis sensibil la procesele relativ recente orizontale. Este important să rețineți că abordări foarte diferite, folosind modele de distribuție de caracteristici structurale lingvistice au sugerat recent că America de Nord și anumite caracteristici, cum [61] , și că ar putea fi chiar un membru al-o zonă lingvistică presupuse inconjoara Pacificul[62] . Acest lucru sugerează faptul că profilurile de stabilitate poate dezvălui legături vechi, probabil, în acest caz, datând popularea original al Americi cel puțin [63] de ani în urmă. Descoperirile noastre oferi unele indicații slab pentru un grup în cadrul Papua-Noua Guinee, și nu poate respinge austro-Tai ipoteza. Lipsa de similitudine între papuas și limbile australian pare să sugereze evenimente distincte demografice care au loc înainte sau după destrămarea Pragului Sahul, [64] și erodează orice semnal de înrudire. În cele din urmă, am găsit sprijin pentru o versiune de Nostratic, precum și pentru un set de bază de Eurasia familii de limbi. De asemenea, întreaga Eurasia a primit un sprijin ca o grupare de familii de limbi. Astfel, metoda noastră pare să sugereze unele legături vechi între familii de limbi eurasiatice pe de o parte, și familiile americane, pe de altă, dar nu este clar dacă aceste conexiuni reflectă genealogie vechi sau fenomene de contact.
Noi credem că nu există nici o contradicție între constatările noastre aici că modelul de variație inter-familiale în limba profilurile de stabilitate de ordin superior are trei componente (universale, limbajul de familie specifice și genealogice / suprafață) și să lucreze sugerând că nu există nici o limbă universalii, în general, [17] , [65] sau universalii tipologice implicational, în special, [7] . Mai precis, tendințele noastre universale pentru anumite caracteristici structurale să fie mai stabil decât alții din familii de limbi (a se vedea, de asemenea, [9] ), sunt doar că: tendințe statisticedeparte de a dicta rigid clasamentul exactă a caracteristicilor în orice familie anumită limbă. Aceste tendințe ar putea duce la "soft" constrângeri cognitive, articulatorii sau auditive sau prejudecati [25] , [66] și / sau proprietăți emergente ale limbilor ca sisteme evolutive culturale a căror funcție principală este de complex de comunicare.Este chiar posibil ca aceste "universale" tendințe reflectă monogenic final al limbajului, mai degrabă decât constrângerile persistente, dar acest lucru ar necesita un conservatorism foarte mare a profilelor de stabilitate. Constatare recentă [7] , [50] în care constrângerile privind schimbările sintactică au un caracter specific filiație este, de asemenea, în concordanță cu ideea de a profilelor de stabilitate reflectă genealogie de bază, deși s-ar putea aștepta de studii mai cuprinzătoare de familii de limbi mai mult pentru a descoperi unele trăsături comune care stau la baza .
Noastre preliminare constatarea că aici caracteristicile structurale ale limbajului indică, de asemenea, evolutia punctat ca vocabularul de bază [36] , precum și faptul că diferitele categorii de caracteristici tind să fie afectate în mod diferit de punctuație în întreaga familii ar putea ajuta la lumina varsat pe procesul de divergență limbajului.Activitatea viitoare trebuie să investigheze cauzele pentru această variație între familii de limbi și categorii de funcții în importanța punctuație.
În concluzie, am constatat că modelul de stabilitate relativă derivate din mai multe caracteristici structurale are atât o componentă universală și o componentă genealogice / arealul. Componenta universal poate oferi perspective în proprietățile sistemelor de limbi, în general, împreună cu prejudecățile lor contribuie cognitive și genetică. Componenta genealogic / Regional poate oferi o privire în procesele antice demografice și lingvistice, cum ar fi popularea America, și promite unele ajunge dincolo de orizontul de timp convențională a metodei comparative în domeniul lingvisticii istorice. În plus, lucrările comparativă la acest nivel superior, mai abstract de analiza poate ajuta pentru a oferi instrumente pentru investigații mai concentrate ale relațiilor istorice în cadrul zonelor geografice: în sugerând caracteristici care tind să fie universal stabil sau stabil în termen de familii de limbi specifice, această metodă poate permite selectarea judicioasă a caracteristicilor structurale pentru filogenetic mai convențional analizează de relații istorice. Sperăm că activitatea viitoare valorificare a de ordin superior proprietățile limbi data ca sisteme evolutive se va dovedi fructuoasă pentru o mai bună înțelegere a limbajului și a evoluției sale.
Materiale și metode populare
Toate analizele raportate aici au fost efectuate folosind open source versiunile statistice R mediu 2.13 și 2.14 [67] .Datele primare
Am folosit aceleași date primare (caracteristici structurale și familii de limbi) și metode pentru estimarea ratelor caracteristicile "de schimbare ca și în [9] , și, prin urmare, vom descrie pe scurt doar le aici. La acestea, am adaugat un nou set de familii de limbi (descrise mai jos), extinderea seturilor de date utilizate în [9] . Mai mult decât atât, vom extinde foarte mult și să completeze analizele prezentate acolo folosind o abordare roman și metodologia, și am mări focalizarea la repartizarea de variație în rândul . familii de limbi, în plus față de tendințele comune, universaleAm colectat date structurale de la Atlas Mondială a structurilor de limbă (în continuare WALS [31] , [32] , disponibil online la http://www.wals.info ), și le-am filtrat prin eliminarea caracteristici, cu un procent ridicat de date lipsă și o acoperire redusă în ceea ce privește numărul de familii [9] . Caracteristicile în Wals au un număr de valori variind între 2 și 9, iar unele dintre aceste caracteristici ar putea fi, fără îndoială, considerată ca conflating două sau mai multe aspecte distincte. Astfel, pentru a controla pentru efectele de codificare și de a studia comportamentul acestor aspecte separat, am codificat caracteristicile fie ca polimorfa (originale rang la nivel de codare din WALS, de exemplu, funcția tonul are trei valori în Wals, și anume "nu tonuri de "," ton simplu "sau" ton de complex ") sau binar (lingvistic informat recodificare, bazat pe valorile Wals, de exemplu, tonul rezultatele în două aspecte: binare tone1 = "nu" față de tonuri de orice tip de ton, și tone2 = "complexul ton "versus" simplu "și" fără tonuri "). A se vedea Materiale S1 pentru lista de caracteristici structurale utilizate aici, descrierea lor și aspectele binare (dacă este cazul) și [9] pentru detalii complete. Ar trebui menționat faptul că, pe partea de sus a problemelor generale privind comparabilitatea categorii tipologice între limbi [18] , WALS introduce mai multe dificultăți de alte. WALS nu furnizează valorile reale pentru mai multe caracteristici (cum ar fi numărul de consoane sau vocale într-o limbă), dar oferă în schimb clasaterezumatele (cum ar fi limbile, cu o "mică", "medie" sau "mare" numărul de vocale), care crește în mod artificial omogenitate în interiorul astfel de clase și de diferențele de la granița dintre clase (de exemplu, un limbaj cu 4 vocalele apartine "mic", dar una cu categoria 5 la "media". Prin urmare, rezultatele noastre poate depinde de aceste caracteristici a WALS (care, cu toate imperfecțiunile sale este in prezent cea mai buna sursa de informații disponibile tipologică, cu o acoperire mare, atât în termeni de limbi și caracteristici), dar aceasta trebuie să fie lăsate pentru studii viitoare pentru a evalua.
Limbile individuale pot fi fie izolate (cum ar fi basca sau ainu ), când nu relații genealogice cu alte limbi pot fi stabilite prin metode lingvistice istorice, sau ele sunt clasificate ca aparținând unei familii de limbi , reprezentând o grupare genealogic, cum ar fi indo-europeană . Ea are să se sublinieze faptul că clasificarea limbilor în entități genealogice (familii de limbi) este departe de a fi un proces simplu și multe dezacorduri persistă cu privire la numărul, structura și componența internă a multor familii de limbi. Pentru unele familii (cum ar fi indo-europeană), acordul este mai mare decât pentru alții, în timp ce unele sunt aprig dezbatut (cum ar fi "altaică") sau, în general, considerate a nu reprezintă unități valabile genealogice (cum ar fi "Khoisan")[2] . Am evitat astfel de judecăți subiective a face noi înșine și a luat loc în "familii de limbi", cum sunt raportate în mai multe surse, fiecare cu propriile sale caracteristici.Am adunat astfel de clasificări genealogice ale limbilor din trei surse diferite: Wals[31] , Ethnologue [34] și anexa Hammarström Harald de a [35] , în scopul de a controla efectul acestor clasificarea s-ar putea avea asupra rezultatelor noastre.Clasificările oferite de WALS și Ethnologue nu sunt independente și cea mai mare parte sunt de acord, dar există, de asemenea, mici diferențe, în special în ceea ce privește gradul de caietul de sarcini al acestor copaci genealogice. În ambele clasificări sunt entități cu personalitate controversată, cum ar fi "Khoisan", "altaică" și "australian", cea mai mare parte respinsă de către lingviști ortodoxe istorice [2] . Clasificările în Wals recunosc, în general, numai trei niveluri ("familie", "Genus" și "Limba"), în timp ce Ethnologue recunoaște cât mai multe niveluri de 14 și 16 Hammarström lui.Familiile lingvistice culese de Harald Hammarström pentru ancheta sa în limba-agricole co-dispersarea ipoteza [35] urmați mai multe criterii stricte, cum ar fi o "demonstrație publică" de afilierea lor genealogic cu ajutorul "metodei ortodoxe comparativă", așa cum este descris de către Campbell și Poser [2] . Momentan nu sunt entități, cum ar fi "Khoisan" sau "australian" prezent aici. Detalii ale acestor familii, inclusiv sursele lor, sunt prezente în anexa la [35] și o versiune actualizată ușor electronică a structurii lor ne-au fost furnizate nouă de către autor în ianuarie 2012. Am folosit aceste fișiere electronice pentru a extrage arborele topologie pentru fiecare familie limbă. Am alocat familii de limbi la 10 zone geografice (a se vedeafigura 2 ) lejer în urma WALS [31] . Această alocare este cea mai mare parte pragmatică, deoarece sporește vizualizarea și prezentarea rezultatelor, fără a afecta în vreun fel pe procesul real de testarea ipotezelor, care poate lua în considerare seturi arbitrare de familii de limbi, așa cum este descris mai jos. Detalii despre familii de limbi utilizate, structura lor și alocarea lor în zonele geografice sunt date în S1 Materiale și figurile 1 și 2 .
Estimarea stabilității
Pentru inferenta a ratelor caracteristicile "de schimbare, am considerat fiecare familie limbă ca un independent, filogenie dat cu caracteristica valorile, de asemenea, având în vedere pentru sfaturi de acest filogenie (limbile existente). Am folosit o abordare filogenetică Bayesian pentru estimarea ratelor de schimbare. Mai precis, pentru a controla efectele anumită metodă pentru estimarea ratelor de schimbare, am folosit două pachete software, utilizat pe scară largă MrBayes 3 [33] și BayesLang personalizat scris, concepute special pentru caracteristicile acestei probleme [9] . În general, metodele bayesiene produc distribuții întregi posterioare ale estimărilor parametrilor (spre deosebire de estimările punctuale unice), iar rezultatele noastre Procedura în o distribuție de ratele estimate pentru fiecare element din setul de caracteristici pentru familii de limbi luate în considerare. Pentru MrBayes 3 am convertit familiile lingvistice într-un set de constrângeri specifică topologia de copac.Outgroup cerute de software-ul pentru estimarea ratei de înrădăcinare și a fost reprezentată la rândul său, de către fiecare dintr-un set mare de limba selectată pentru izolatele integralitatea lor caracteristică în Wals. Cu acestea, MrBayes 3 a fost folosită pentru a deduce lungimi de ramură, state antice și ratele de schimbare pentru caracteristicile care fac obiectul anchetei. De asemenea, BayesLang nu are nevoie de o lungime ramură, ci doar o topologie copac înrădăcinată reprezentată de familii de limbi. Se estimează, de asemenea, filiale, lungimi state vechi și ratele de schimbare pentru caracteristicile care fac obiectul anchetei, cu diferența că ratele reprezintă numărul minim de schimbări necesare pentru stat ancestral estimată a duce în statele observate dat modelul evolutiv asumat pentru structurală caracteristică. Această estimare este asemănător cu un model de parcimonie maximă și a fost special ales pentru a utiliza o metodă de diferit de la MrBayes 3. Pentru mai multe detalii, vă rugăm să consultați [9] . Atât MrBayes 3 și ipotezele BayesLang parts generale, cum ar fi modelele de evoluție pe filogeniile de arbori și de calcul a riscului de filogeniile astfel, având în vedere datele observate, modele evolutive și parametrii lor [68] ,[69] . Principalele diferențe sunt că în timp ce MrBayes 3 a fost conceput pentru seturile de date biologice (și am tratat caracteristicile polimorfice ca date morfologice și caracteristicile binare ca date de restricție), BayesLang a fost proiectat pentru a deduce evolutia cifrei de date lingvistice structurale pe copac rădăcini fixe topologii și-l acceptă, de asemenea, mult mai rafinate (chiar definită de utilizator), modele de schimbare pentru o caracteristică dată. O altă diferență discutat mai sus se referă la tipul de ratele estimate. Folosind aceste metode pentru date lingvistice structurale ar putea induce anumite prejudecăți. De exemplu, tratarea datelor lingvistice structurale ca restricție / morfologice în MrBayes 3 ar putea afecta estimarea ratelor, în timp ce estimarea parcimonie-ca și în BayesLang ar putea fi afectate de ramuri lungi. Cu toate acestea, așa cum este detaliat mai jos, corelațiile ridicate între rezultatele obținute de aceste pachete software doi pare să sugereze că aceste prejudecăți nu poate fi important. O altă problemă este posibil, de obicei, ridicat în ceea ce privește aplicarea unor metode filogenetice de limbi, se referă influența nu modelarea proceselor răspândite orizontale care afectează limba. Cu toate acestea, așa cum este detaliat îndiscuție , credem că pentru acest tip special de anchetă, de contact este implicit inclusă ca o altă sursă de schimbare a limbajului, contribuind la instabilitatea dintre caracteristicile de afectate.Cu acestea, există în total 12 seturi de date , fiecare cuprinzând un pachet software (M rBayes sau B ayesLang), o date de codificare ( B veterinare sau P olymorphic) și oclasificare genealogic ( E thnologue, W ALS sau H ammarström). Vom nota aceste seturi de date folosind literele inițiale ale pachetului de programe, codificarea datelor și clasificare genealogică: MBE , MBW , MBH , MPE , MPW , MPH , BBE , BBW , BBH ,BPE , BPW si HBP (vezi materiale S1 ). În general, am analizat un total de 56 familii de limbi reprezentate de 240 filogeniile unice compuse dintr-un total de 3836 de limbi, și 70 și 86 polimorfi caracteristici binare.
După cum sa explicat în [9] , pentru a putea compara aceste rate de schimbare a lungul familii de limbi și seturi de date fără să își asume calibrare, am convertit laratele absolute produse de pachete software filogenetice la ranguri standardizate relative variind între 0.0 (cea mai stabila) la 1.0 ( cea mai instabilă), după cum urmează. Pentru o distribuție posterioară a ratelor absolute (reprezentând rezultatele pentru o caracteristică într-o limbă în familie un set de date), am extras una câte una pentru fiecare observație posterioară a ratelor și a clasat-le (folosind gradul mediu de legături); următor, am normalizat aceste rangurile pentru a intervalul de 0.1 cum se explică în detaliu mai jos. Pentru fiecare dintre cele 12 seturi de date, există o serie de caracteristici structurale
Având în vedere utilizarea roman al lui Harald Hammarström [35] mai mult "ortodox" clasificarea aici, este important să se cuantifice cat de bine stabilități estimate folosind-o acord cu aceste WALS estimate folosind și Ethnologue. În acest scop, am efectuat un Principal Component Analysis [70] cu privire la clasamentul produse de binar 6 și 6 seturi de date polimorfi separat. Pentru ambele, primul component principal (
Evolutia punctat
În scopul de a estima existența și importanța evoluției punctat [37] cu privire la caracteristicile structurale ale limbajului, am utilizat o metodologie mult mai simplu decât [36] . Metoda noastră se dorește a fi o explorare inițială a acestui subiect, și se bazează pe principiul că rezultatul evoluție treptată și punctat în relațiile dintre diferitede lungime a traiectoriei (suma lungimii tuturor ramurilor de legătură rădăcina arborelui la un nod terminal) și numărul de noduri pe calea: nici o corelație între două pentru evoluția graduală și o corelație pozitivă pentru un proces de punctuational [71].Având în vedere faptul că clasificarea WALS limitează adâncimea de arbori la 3, ne vom concentra aici numai asupra Ethnologue și clasificările Hammarström lui, rezultând în 8 seturi de date ( BBE , BBH , BPE , HBP , MBE , MBH , MPE și MPH ).Pentru fiecare set de date și fiecare copac posterioara, am calculat corelație (Pearson rși a lui Spearman
Pentru fiecare din cele șapte categorii de caracteristici cum sunt definite de WALS acoperite de setul de date nostru ( Morfologia , Categorii nominale , sintaxă nominală ,fonologie , în Clauzele simple , Categorii verbale și ordinea cuvintelor ) am estimat evolutia punctual numai pentru cele patru seturi de date folosind clasificarea Hammarström lui ( BBH , HBP , MBH și MPH ), din cauza costurilor ridicate de calcul. Mai mult decât atât, având în vedere faptul că nu toate familiile să acopere toate cele șapte categorii, am considerat trei cazuri definite de setul de familii care acoperă cel puțin
Această metodă simplă pentru estimarea evoluției rolul punctat pentru caracteristicile structurale ale limbajului nu supune controlului pentru strămoși comun între limbile de aceeași familie și nici nu-l proteja împotriva "nodul-densitate artefact", probabil ca rezultat o estimare a umflat Contribuția de evoluție punctat [36] , [37] , [71] . Prin urmare, aceste rezultate ar trebui să fie luate în orientativă, și mai complex, dar, de asemenea, mai multe consumatoare de timp metode trebuie să fie utilizate pentru a oferi o estimare mai bună a acestui efect. Cu toate acestea, având în vedere dimensiunile mari efectele găsit și coerența acestora în seturile de date și pachetele software ( Materiale S1 ), estimările noastre sunt cel mai probabil relativ corecte.
Profilul de stabilitate a familiei de limbi
Având în vedere un set de date, să ne notăm în rândurile medii standardizate de stabilitate ale elementelor structuraleAvând în vedere două familii de limbi,
Pentru a face lucrurile clare, să ne considerăm doar două caracteristici,
"Forma" Profiluri de stabilitate
Profilurile de stabilitate alePrima metodă presupune generarea 10.000 de seturi aleatoare independente de Mpuncte în stabilitatea hiper-cub folosind o distribuție uniformă între 0.0 și 1.0 pentru a genera N coordonatele pentru fiecare din cele M puncte, și compararea acestor seturi aleatoare a observat de fapt, un set de stabilitate profiluri. Am folosit distanta de lacel mai apropiat vecin- si medie distanta dintre puncte ca statisticile rezumat pentru fiecare set de M puncte (inclusiv cele de fapt observate). Am comparat apoi un rezumat al statisticilor din setul observate de profile de stabilitate pentru distribuția de statistici rezumative pentru 10.000 de seturi generate aleatoriu pentru a evalua agregare sau dispersie a datelor reale comparativ cu valorile așteptate. Mai precis, am obținut un empiric p -valoare care reprezintă proporția de seturi aleatorii, cu mici cel mai apropiat vecin, sau înseamnă distanțe decât de fapt observate set de profile de stabilitate ( materiale S1 ).
Pentru a doua metodă am generalizat lui Ripley K funcția [39] pentru
în cazul în care
Comparând stabilitate structurală Peste Metode
Problema stabilității de caracteristici structurale este unul important pentru lingvistica istorice și în special pentru tipologia lingvistică și mai multe abordări au fost propuse în literatura de specialitate. Cu toate acestea, având în vedere complexitatea proceselor care afectează schimbarea limbajului, există multe moduri de a conceptualiza și operaționaliza stabilitate. În scopul de a înțelege aceste abordări și relațiile lor cu altele, primul autor, împreună cu Michael Cysouw (Dediu, D. & Cysouw, M. în curs de pregătire , unele aspecte structurale ale limbii sunt mai stabile decât altele: O comparare a șapte metode) sunt în prezent lucrează la un studiu sistematic și compararea de 7 metode diverse de la literatura de specialitate tipologică lingvistică.Metodele de față sunt:
- Cysouw si colegii [19] ia în considerare coerența distribuției trans-lingvistice a o caracteristică individuală cu modelul generat de mai multe caracteristici, și ei propun trei cuantificari ale acestei măsuri bazata pe corelatia Mantel, o coerență și o metodă de rang [19] ;
- Parkvall [20] propune să se distingă caracteristicile care tind să fie vertical transmis de la cele care sunt usor de borrowable, cuantificate folosind indicele Herfindahl-Hirschman indicele (sau coeficientul Gini ) calculat în întreaga unități genealogice și suprafață;
- Wichmann și colegii, și mai ales Wichmann și Holman [22] au o concepție predominant filogenetică a stabilității în cazul în care o caracteristică stabilă tinde să fie împărțite între conexe, dar nu printre limbile independenți;
- Maslova [21] propune o metodă relativ similar, bazat pe estimarea probabilității de tranziții între valorile artistice;
- în cele din urmă, metoda descrisă aici [9] este o abordare complet filogenetice Bayesian pentru estimarea stabilității de caracteristici structurale.
Distanțe geografice între familii de limbi
Având în vedere două familii lingvisticeAstfel, pentru fiecare pereche de familii de limbi (
Caracteristici Maximizarea Corelația dintre stabilitate și Distanțe geografice
Am cautat pentru aceste subgrupuri de caracteristici care maximizează corelația Mantel între stabilitate și distanțe geografice, după cum urmează. Să ne considerămAm folosit un algoritm genetic (cum a fost transpusă în pachetul R genalg 0.1.1) pentru a căuta pentru subgrupuri
Rezultatele căutării într-un set de 500 de populații de 200 genomi (o populație de generație), fiecare dintre aceste gene au 100000 asociate o valoare a functiei de fitness, în acest caz, corelarea Mantel
În general, procesul de căutare a fost foarte rapid, ajungand la valoarea optimă a corelației Mantel
Combinarea p -valori de la non-independente Experimente
Cele 12 seturi de date reprezintă diferite combinații de pachete software, codificările și clasificări lingvistice genealogice, dar ele nu reprezintă statistic experimente independente din cauza dependențelor de la mai multe niveluri:- caracteristicile structurale și valorile lor vin formează o singură sursă, și anume WALS;
- toate codificările polimorfice și binare sunt semnificativ legate de;
- două dintre clasificările genealogice lingvistice nu sunt independente, astfel cum a fost în mod explicit WALS inspirat de Ethnologue;
- cele două pachete software utilizează aceeași aparatură fundamentală matematic și statistic (Bayesian inferență filogenetică).
Există mai multe metode de bine-stabilite pentru combinarea semnificație ( p -valoare) și efectul de informații de la dimensiunea independente teste ale aceluiașiipoteza nulă
dar a priori nu sunt adecvate pentru cazul nostru, datorită menționat non-independență.Metode de combinare depinde p -valori, cu toate acestea, nu sunt la fel de bine dezvoltate și au diferite ipoteze, care nu sunt ușor de verificat în situații reale. Cu toate acestea, am selectat trei astfel de metode de literatura de specialitate și implementate-le în R [67] (a se vedea Materiale S1 pentru punerea lor în aplicare cod R):
- Hartung E [72] Metoda presupune corelații constante de-a lungul testelor și oferă, de asemenea, o estimare a acestei corelații;
- Makambi 's [73] este o extensie a metodei lui Fisher pentru cazurile pozitiv corelate dependente și își asumă omogenitate a corelațiilor inter-test; oferă, de asemenea, o estimare a acestei corelații și
- Simes " [74] Abordarea este robust pentru dependență, dar nu calcula un combinat p -valoare, în schimb în cazul în testarea ipotezei nule poate fi respinsă pentru un anumit
nivel de informare combinate cuprinse în testele individuale.
Toate cele cinci metode sunt de acord foarte bine pe respingere sau nu ipoteza nulă la un convențional
Cu toate acestea, vom lua o conservatoare atitudine și să prezinte în combinat p -valoare mai mare a celor 4 p -valorile date de Fisher , transformatei-z , Hartungși Makambi . Vă rugăm să rețineți faptul că această procedură, în timp ce paza împotriva alarme false, are efecte contraintuitiv, cum ar fi scăderea aparent dramatică a p -valorile atunci cand control pentru geografie, în unele cazuri (de exemplu, pentru America, a se vedea tabelul 2 ). Cu toate acestea, acestea sunt artefacte din cauza ipoteze diferite ale metodelor de combinare p -valori, după cum se poate vedea clar înS1 Materiale . În cele din urmă, având în vedere că luăm această poziție foarte conservatoare în combinarea cele 12 seturi de date, ne-am decis să nu pentru a corecta pentru comparații multiple. Dar, chiar folosind o extrem de conservatoare corecție Bonferroni în toate grupurile testate (a se vedea mai jos), încă în rezultate, de exemplu, in America formează un grup coerent atunci cand control pentru geografie (
Testarea Rezistența de grupuri de familii de limbi
În general, să ne considerăm un subset deMai precis, am considerat distanța de stabilitate prime (de exemplu, necorectată) și geografic medie cu corecție între familii de limbi. Am generat 10,000 subseturi aleatorii de familii de limbi
În continuare, am luat subseturi generate aleator R și le-a folosit pentru a deduce ce distanța medie între stabilitatea familiilor în A ar fi fost daca o fost doar un alt subset aleatoare de familii de limbi. Mai precis, am regresat liniar distanța medie de stabilitate pe distanța geografică dintre familiile lingvistice în subseturi aleatorii (fiecare subset aleatoare R reprezintă un singur punct de date în acest regresie) si am prezis valoarea distanței de stabilitate, având în vedere geografic medie observată distanța dintre familiile din A . Acest lucru ne spune cum a profilelor de stabilitate din Aar trebui să fie legate între ele pentru un set de familii despărțite de distanța geografică dată. Apoi ne-am folosit de predicție interval de încredere de 95% din această regresie pentru a testa ipoteza (și obține un corespondent p -valoare), care a familii de limbi din A sunt mult mai compacte decât se preconiza de șansă în L atunci cand control pentru geografie.
Astfel, distanța de stabilitate necorectată (brut) înseamnă testează ipoteza că familii de limbi din A au profiluri foarte similare de stabilitate în raport cu întregul set de familii, în timp ce versiunea corectată ia, de asemenea, în considerare distanțele geografice dintre ele. În cele mai multe cazuri, cele necorectate p -valorile sunt mai mici decât cele corectate (a se vedea Materiale S1 ): de perechi t-teste între necorectate si geografie-corectate p -valorile sunt negative, cu excepția, în mod interesant, pentru Europa de Sud, Centrală și America de Nord față de America, caz în care corectarea pentru geografie vă ajută să evidențiați similitudine în aceste domenii în contextul general al similitudinii familii americane. Cu toate acestea, nu este clar dacă măsurile de prime sau corectată sunt mai potrivite pentru studiul nostru, deoarece acestea reprezintă concepte ușor diferite de grupare în spațiu de stabilitate.Mai precis, având în vedere că ambele zonale (orizontal) (fenomene de împrumut, schimbare limba, etc) și relații verticale genealogice implică, de obicei, populațiile vecine punct de vedere geografic, controlul de la distanță geografică s-ar putea, de fapt, eliminarea unui factor esențial de cauzalitate și nu doar o pacoste. De aceea, ne-am testat și raportate ambele cazuri.
O limitare principală a acestei metode este puterea sa de mic pentru a testa subseturi mari A la L , deoarece există puține subseturi posibile aleatorii R echivalentă cu A . De aceea, nu putem testa coerența de seturi mari de familii de limbi care acoperă, de exemplu, Eurasia și America.
Sprijinirea Informații Top
S1 electronice materiale suplimentare.Conține mai multe informații despre datele primare și codificarea acesteia (S1 Mese, S3, S4 și S15), cu privire la profilurile de stabilitate (tabelele S2 și S5, și Cifre S1-S14), implicarea de caracteristici în corelație între stabilitate și distanțe geografice (Tabelele S6-S13), combinate cu p -valori (tabelele S14 și S16) și codul de punere în aplicare aceste metode R (tabelul S17), precum și mai multe rezultate în ceea ce privește evoluția punctual de caracteristici structurale (tabelele S18 S19 și S15, și Cifre- S18).
(PDF)
Aprecieri Sus
Ne mulțumim Fiona Jordan, Nick Enfield, Michael Dunn, Michael Cysouw, Alexandra Dima și trei comentariile anonime pentru comentarii și sugestii, și Hammarström Harald pentru punerea la dispoziție în format electronic, pe familii de limbi care le-a colectat.Contribuții autori Top
Conceput și proiectat de experimente: DD SCL. Efectuat experimente: DD. Analiza de date: DD. A contribuit reactivi / materiale / instrumente de analiză: DD. Scris de hârtie: DD SCL.Referinte Sus
- Campbell L (2004) lingvistică istorice: o introducere. Edinburgh: Edinburgh University Press.
- Campbell L, Poser WJ (2008) Clasificarea Limba: Istorie și metodă. Cambridge University Press.
- Croft W (2008) lingvistică evolutive. Annu Rev Anthropol 37:. 219-234 GĂSIȚI ACEST ARTICOL ON-LINE
- PAGEL M (2009) Limbajul uman ca un replicator cultural transmis. Nat Rev Genet 10:. 405-415 GĂSIȚI ACEST ARTICOL ON-LINE
- PAGEL M, Atkinson zilnic, Meade A (2007) Frecvența de cuvânt utilizare prezice ratele de evolutia lexicale de-a lungul istoriei indo-europeană. Natura 449:. 717-721 GĂSIȚI ACEST ARTICOL ON-LINE
- Dunn M, Terrill A, Reesink G, Foley RA, SC Levinson (2005) phylogenetics structurale și de reconstrucție a istoriei limbii antice. Știință 309:. 2072-2075GĂSIȚI ACEST ARTICOL ON-LINE
- Dunn M, Greenhill SJ, Levinson SC, Gray RD (2011) Evolved structura limbii arată tendințele lineagespecific în cuvântul de ordinul universalii. Natura 473:. 79-82GĂSIȚI ACEST ARTICOL ON-LINE
- Greenhill SJ, Atkinson zilnic, Meade A, Gray RD (2010) forma și ritmul de evoluție limbajului. Proc R Soc Lond B Biol Sci 277:. 2443-2450 GĂSIȚI ACEST ARTICOL ON-LINE
- Dediu D (2011) O abordare filogenetică Bayesiana pentru estimarea stabilității caracteristicilor lingvistice și genetice biasing de ton. Proc R Soc Lond B Biol Sci 278:. 474-479 GĂSIȚI ACEST ARTICOL ON-LINE
- Hunley K, M Dunn, Lindstrm E, G Reesink, Terrill A, et al. (2008) coevoluției genetică și lingvistice, în nordul insulei Melanezia. PLoS Genet 4:. E1000239GĂSIȚI ACEST ARTICOL ON-LINE
- Swadesh M (1952) datarea Lexicostatistic de contacte preistorice etnice. Am proc Philos Soc 96:. 452-463 GĂSIȚI ACEST ARTICOL ON-LINE
- Tadmor U, Haspelmath M, B Taylor (2010) Borrowability și noțiunea de vocabularul de bază. Diachronica 27:. 226-246 GĂSIȚI ACEST ARTICOL ON-LINE
- PAGEL M, A Meade (2006) Estimarea ratelor de schimb lexicale pe arbori filogenetici de limbi. În: P Forster, Renfrew C, editori, metode filogenetice și preistoria limbi, Cambridge, Marea Britanie: McDonald Institutul de Cercetare Arheologică. 173-182.
- Holman EW, Wichmann S, Brown CH, Velupillai V, Mller A, et al. (2008) Explorări în limba clasificarea automata. Folia Linguistica 42:. 331-354 GĂSIȚI ACEST ARTICOL ON-LINE
- Renfrew C, McMahon A, Trask L, editori (2000) aprofundate în domeniul lingvisticii istorice Timp. Cambridge, Marea Britanie: McDonald Institutul de Cercetare Arheologică.
- Nichols J (1999) Diversitatea lingvistică în spațiu și timp. Chicago: University of Chicago Press.
- Levinson SC, Evans N (2010) E timpul pentru o schimbare în lingvistica: răspuns la un comentariu la "Mitul universalii lingvistice". Lingua 120:. 2733-2758 GĂSIȚI ACEST ARTICOL ON-LINE
- Haspelmath M (2007) pre-stabilite categorii nu există: consecințele pentru limbaj de descriere și tipologia. Tipologia lingvistică 11:. 119-132 GĂSIȚI ACEST ARTICOL ON-LINE
- Cysouw M, Albu M, rochie de A (2008) coerența caracteristica Analizare folosind matrice neasemănare. Stuf 61:. 263-279 GĂSIȚI ACEST ARTICOL ON-LINE
- Parkvall M (2008) Ce părți ale limbajului sunt cele mai stabile? Stuf 61:. 234-250GĂSIȚI ACEST ARTICOL ON-LINE
- Maslova E (2000) O abordare dinamică a verificării universalii de distribuție.Tipologia lingvistică 4:. 307333 GĂSIȚI ACEST ARTICOL ON-LINE
- Wichmann S, Holman EW (2009) Evaluarea stabilității în timp pentru caracteristici lingvistice tipologice. München: LINCOM Europa. Disponibil:http://email.eva.mpg.de/wichmann/Wichman nHolmanIniSubmit.pdf .
- Holman EW, Schulze C, D Stauffer, Wichmann S (2007) cu privire la relația dintre diversitatea structurală și distanța geografică dintre limbi: observații și simulări pe calculator. Tipologia lingvistică 11:. 395-423 GĂSIȚI ACEST ARTICOL ON-LINE
- Kluckhohn C, H Murray (1953) Formarea Personalitate: determinanților. În: Kluckhohn C, H Murray, editori, Personalitate în natură, societate și cultură, New York: Alfred A. Knopf. 53-70.
- Dediu D, Ladd DR (2007) ton lingvistică este legată de frecvența populației a haplogrupuri de adaptare a două gene marimea creierului, ASPM și Microcephalin.Proc Natl Acad Sci Statele Unite ale Americii 104:. 10944-9 GĂSIȚI ACEST ARTICOL ON-LINE
- Christiansen MH, Chater N (2008) Limba ca formă de creier. Compor Brain Sci 31: 489-508; discuții 509-58.
- Meillet A (1903) Introducere à l'étude des langues comparativ indo-Européennes.Paris: Hachette.
- Proulx SR, Promislow DEL, Phillips PC (2005) gândirea de rețea în ecologie și evoluție. Tendințe Ecol Evol 20:. 345-353 GĂSIȚI ACEST ARTICOL ON-LINE
- Jain R, Rivera MC, Lacul JA (1999) transfer de gene orizontal printre gene: Ipoteza complexitate. Proc Natl Acad Sci Statele Unite ale Americii 96:. 38013806 GĂSIȚI ACEST ARTICOL ON-LINE
- Aris-Brosou S (2005) Factorii determinanți ai evoluției adaptare la nivel molecular: ipoteze de complexitate extinsă. Mol Biol Evol 22:. 200-209 GĂSIȚI ACEST ARTICOL ON-LINE
- Haspelmath M, Uscător de MS, Gil D, B Comrie, editori (2005) atlas lume a structurilor lingvistice. Oxford, Marea Britanie: Oxford University Press.
- Uscător de MS, Haspelmath M (2011) Atlasul lumii structurilor lingvistice on-line.Disponibil: http://wals.info/ .
- Ronquist F, Huelsenbeck JP (2003) Mrbayes 3: Bayesian inferență filogenetic sub modele mixte. Bioinformatica 19:. 1572-1574 GĂSIȚI ACEST ARTICOL ON-LINE
- Lewis MP, editor (2009) Ethnologue: Limbile lumii. Dallas, Texas: SIL International, editia 16. Disponibil: http://www.ethnologue.com/ .
- Hammarström H (2010) Un test pe scară largă a ipotezei dispersare limba agricultura. Diachronica 27:. 197-213 GĂSIȚI ACEST ARTICOL ON-LINE
- Atkinson zilnic, Meade A, C Venditti, Greenhill SJ, Pagel M (2008) Limbi evolua în exploziile punctuational. Știință 319: 588 -.
- Venditti C, A Meade, Pagel M (2006) Detectarea artefact nodul densitate în reconstrucție filogenie. Sistem Biol 55:. 637-643 GĂSIȚI ACEST ARTICOL ON-LINE
- O Schabenberger, Gotway CA (2005) Metode statistice pentru analiza de date spațiale. Texte în știință statistică. Boca Raton, Florida: Chapman & Hall / CRC Press.
- Ripley B (1976) Analiza de ordinul al doilea a proceselor de puncte staționare. J Appl Probab 13:. 255-266 GĂSIȚI ACEST ARTICOL ON-LINE
- Cox T, Cox M (1994) Multidimensional scalare. Londra, Marea Britanie: Chapman & Hall.
- Bryant D, Moulton V (2004) Neighbor-net: o metodă aglomerativ pentru construirea de rețele filogenetice. Mol Biol Evol 21:. 255-265 GĂSIȚI ACEST ARTICOL ON-LINE
- Huson DH, Bryant D (2006) Aplicarea rețelelor de filogenetice în studiile evolutive.Mol Biol Evol 23:. 254-267 GĂSIȚI ACEST ARTICOL ON-LINE
- N Mantel (1967) depistarea bolii de clustering și o abordare generalizată regresie.Rac Res 27:. 209-20 GĂSIȚI ACEST ARTICOL ON-LINE
- Renfrew C, D urzica, editori (1999) Nostratic: examinarea unei macrofamily lingvistică. Cambridge, Marea Britanie: McDonald Institutul de Cercetare Arheologică.
- Fisher R (1932) Metode statistice pentru lucrători de cercetare. Londra: Oliver și Boyd.
- Stouffer S, Suchman E, DeVinney L, Star S, Williams RJ (1949) soldat american, volumul 1. Princeton: Princeton Univ. Apăsați.
- Reid L (2006) austro-Tai ipoteze. În: Brown K, editor, enciclopedie de limbă și lingvistică, Elsevier Science Ltd. ediția a 2, 740-741.
- Haspelmath M, Tadmor U, editori (2009) Loanwords în limbile lumii. Berlin: Mouton de Gruyter.
- Un McMahon, McMahon R (2005) Clasificarea Limba de numere. Oxford: Oxford University Press.
- Levinson SC, Greenhill SJ, Gray RD, Dunn M (2012) dependențelor tipologice universale trebuie să fie detectabilă în istoria familii de limbi. Tipologia lingvistică 15. În presă.
- Thomason SG, Kaufman T (1988) Limba de contact, creolization, si lingvistica genetice. Berkeley: University of California Press.
- Haspelmath M, Tadmor U (2009) Lumea loanword de baze de date (Wold).München: Max Planck pentru biblioteca digitală. Disponibil:http://wold.livingsources.org/ .
- Greenhill SJ, TE Currie, Gray RD (2009) Are de transport pe orizontală invalida filogeniile culturale? Proc R Soc Lond B Biol Sci 276:. 2299-2306 GĂSIȚI ACEST ARTICOL ON-LINE
- Currie TE, SJ Greenhill, Mace R (2010) Este de transport pe orizontală într-adevăr o problemă pentru metodele comparative filogenetice? un studiu de simulare folosind trăsăturile culturale continue. Philos Trans R social Lond B Biol Sci 365:. 3903-3912 GĂSIȚI ACEST ARTICOL ON-LINE
- Bapteste E, Y Boucher (2008) transfer de gene laterală contestă principiile sistematicii microbiene. Tendințe Microbiol 16: 200-207. GĂSIȚI ACEST ARTICOL ON-LINE
- Brssow H (2009) copac nu atât de universal al vieții sau locul de viruși în lumea vie. Philos Trans R social Lond B Biol Sci 364:. 2263-2274 GĂSIȚI ACEST ARTICOL ON-LINE
- Dagan T, W Martin (2006) arbore de un procent. Genomului Biol 7:. 118 GĂSIȚI ACEST ARTICOL ON-LINE
- Ape MR, Forman SL, Jennings TA, Nordt LC, Driese SG, et al. (2011) Zară Creek complexă și originile Clovis la L. Debra site-ul Friedkin, Texas. Știință 331:. 1599-1603 GĂSIȚI ACEST ARTICOL ON-LINE
- E Vajda (2010) O legătură siberian cu Na-Dene limbi. În: J Kari, Potter B, editori, conexiune Dene-Yeniseian, Fairbanks, Statele Unite ale Americii: Universitatea din Alaska Fairbanks, documentele antropologice de la Universitatea din Alaska. 100-118.
- Campbell L, T Kaufman, Smith-Stark TC (1986) mezo-america ca o zonă lingvistică. Limba 62:. 530-570 GĂSIȚI ACEST ARTICOL ON-LINE
- Wichmann S, Holman EW, Stauffer D, Brown CH (2011) Asemănările dintre limbi ale Americi: O explorare a probelor WALS. Jurnalul de relatie Limba 5:. 130-134GĂSIȚI ACEST ARTICOL ON-LINE
- Bickel B, J Nichols (2006) Oceania, Rim Pacic, și teoria de zone lingvistice. În: Berkeley, CA: Proceedings of reuniunea anuala a 32-a Societatii Berkeley Lingvistică.
- Ape MR, Stafford TW, McDonald HG, Gustafson C, Rasmussen M, et al. (2011) Pre-Clovis mastodont vânătoare 13800 ani în urmă, la site-ul Manis, de la Washington. Știință 334:. 351-353 GĂSIȚI ACEST ARTICOL ON-LINE
- Reesink G, Singer R, Dunn M (2009) Explicarea diversitatea lingvistică a Pragului Sahul, folosind modele de populație. PLoS Biol 7:. E1000241 GĂSIȚI ACEST ARTICOL ON-LINE
- Evans N, SC Levinson (2009) Mitul universalii lingvistice: Diversitatea lingvistică și importanța sa pentru științele cognitive. Compor Brain Sci 32:. 429-492 GĂSIȚI ACEST ARTICOL ON-LINE
- Dediu D (2011) Sunt limbi cu adevărat independente de gene? Dacă nu, ce ar fi o diversitate genetică prejudecată care afectează limba arata? Hum Biol 83:. 279-296 GĂSIȚI ACEST ARTICOL ON-LINE
- R Dezvoltare Core Echipa (2011) R: Un limbaj și mediu pentru calcul statistic. R Fundația pentru statistice Computing, Viena, Austria. Disponibil: http://www.R-project.org/ . ISBN 3-900051-07-0.
- Felsenstein J (2004) Deducerea filogeniile. Sunderland, Massachusetts: Sinauer Associates Inc
- Huelsenbeck JP, Ronquist F, R Nielsen, Bollback JP (2001) inferență Bayesiana de filogenie și impactul acesteia asupra biologia evoluționistă. Știință 294:. 2310-2314 GĂSIȚI ACEST ARTICOL ON-LINE
- Jolliffe I (2002) Componenta Analiza principală. Seria Springer în Statistică. New York: Springer Verlag, ediția 2.
- PAGEL M, Venditti C, A Meade (2006) Contribuția mare punctuational de speciație la divergențe evolutive la nivel molecular. Știință 314:. 119-121 GĂSIȚI ACEST ARTICOL ON-LINE
- Hartung J (1999) O notă privind combinarea testelor dependente de semnificație.BIOM J 41:. 849855 GĂSIȚI ACEST ARTICOL ON-LINE
- Makambi K (2003) ponderat invers chi-pătrat metoda pentru testele de semnificație corelate. J Appl Stat 30:. 225-234 GĂSIȚI ACEST ARTICOL ON-LINE
- Simes R (1986) o procedură îmbunătățită Bonferroni pentru mai multe teste de semnificație. Biometrika 73:. 751-754 GĂSIȚI ACEST ARTICOL ON-LINE
Niciun comentariu:
Trimiteți un comentariu